來源: https://code.fb.com/production-engineering/open-sourcing-oomd-a-new-approach-to-handling-ooms/
專案: https://github.com/facebookincubator/oomd
專案: https://github.com/facebookincubator/oomd
儘管 Facebook 以 OOM Killer 來說明 OOMD, 但以 OOMD 在功能性上的描述以及 GitHub 專案上充斥著 detector 字眼, OOMD 應為 Out-Of-Memory Detector 的縮寫.
Facebook 旗下有著各式各樣的服務產品: News Feed, Messenger, Instagram, WhatsApp, Oculus 等等. 這些服務產品系統是基於散佈各地並以百萬計的伺服器來稱起. 當隨著基礎建設的與時地擴增, Facebook發現其主機與網路硬體涵蓋了數個世代. 橫跨多代環境的一個副作用是新版軟體或先配置更改可能導致系統在一台主機運行正常但在另一台主機上有著記憶體不足的問題.
Facebook 發現 Linux Kernel 中的 OOM Killer 有著處理時機過晚的情形,因此常會讓系統落入一種競逐資源而不斷地變換狀態的 Livelock 狀態. 為此目的 Facebook 才開發了 OOMD, 以不同的方式來解決記憶體不足的問題. (champ: 而與 Linux OOM Killer 最大的不同點有二: 一者為在於這是個 userspace 方案, 再者為 OOMD 是以預防的思維來面對 OOM 問題 ) OOM 其設計提供了兩個關鍵的功能特性:
- pre-OOM Hook: pre-OOM Hook 主要目的在於軟體系統受到 OOM 威脅之前, 先提供對於對 OOM 問題的預警.
- plugin system: 提供管理者能夠客製化在主機上對於每個工作負載的處理方式. 這主要在於提供了記憶體不足的問題更佳彈性的處理方式.
Linux OOM Killer 的主要職責在於保護 kernel, 使主機能正常運行; 在終止特定 process 來達成此目的時, 其並不會注意到該 process 背後可能的重要性. 因此當 OOM Killer 運作時存在著在主機上運行的應用程式都將乘受著重大風險. (champ: 對於 Facebook 這類公司而言, 風險就代表著損失的可能, OOM Killer 並沒有提供任何選擇, 相較直接終止帶來的服務終止, 使用者抱怨, 管理者發現與回復有著龐大的延遲. 在商業上應用會希望提供損失程度不同的方案選擇, 像是主機主動增加延遲, 積極地減少服務量, 背景持續將低重要性資料寫到 HDD/SSD/NVMs, 轉換為較少損失的方式來維持系統的可操做與控制性)
OOMD 的客製方案基於了兩個關鍵性的發展:
- Pressure Stall Information (PSI): 這是一個由 Facebook 所開發正準備合入 linux upsteam 的系統工具. PSI 追蹤著三個系統主要資源: CPU, Memory 與 I/O, 觀察這些資源隨著時間的使用變化. 藉由回報因資源短缺造成的時間損失, 以此來提供整體工作負載可量化的測量.
- Cgroup2: cgroup 為 linux 上用來做資源管理的系統. cgroup2 為新一代的設計. 而 OOMD 利用其複雜的精算機制來確認每個工作是否正常地運作.
由上述可以得知, 並非在一個系統上執行 OOMD 後就解決了問題. OOMD 是個對於系統資源提供的資訊系統, 以及預警發佈的機制. 必須有效解讀與利用 OOMD 提供的資訊, 並針對 OOM 發生前預先處理的方式有著事先的設計與規劃. OOMD 才算是正確的導入, 並且才能發揮最大的功效.
Facebook 稱實際運作上, 以此完全消弭了長達 30 分鐘的 livelock. 此外有著相關的實驗數據, 像是:
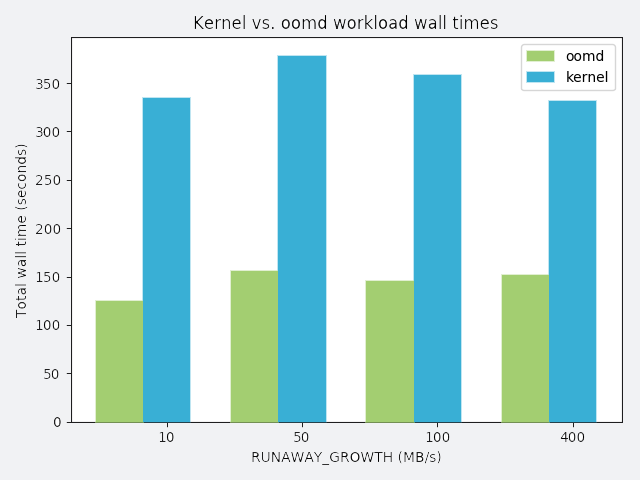
在程度不等的記憶體流失速度(a process that slowly leaks memory)下, 工作負載. 實驗所用的工作負載所需時間為 120秒,高於 120 秒時間都可以視為效能的降低. 由上圖可以比較使用 OOMD 不使用的情況下完成工作的時間. OOMD 僅有著小部分的效能耗損. 此外還有另外的兩個實驗, 詳情就留給大家自己研究.



沒有留言:
張貼留言